Model Selection + Assumptions + Intro to Logistic Regression
Lecture 23
2025-04-10
Warm-up
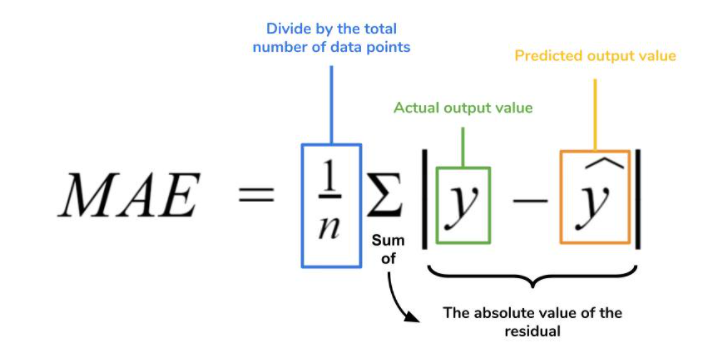
Last class, we introduced how to evaluate models using a metric called Mean Absolute Error. Walk me through this process. Specifically…
When would we use a metric like MAE to evaluate models?
How do we go about this process?
Using the terms testing, and training data
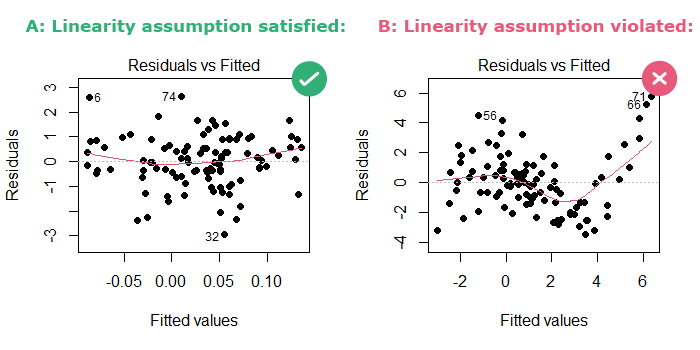
Linearity

Residual vs Fitting plot
the residuals (the difference between observed and predicted values) are plotted on the y-axis and the fitted (predicted) values are on the x-axis.
Logistic regression
– This type of model is called a generalized linear model
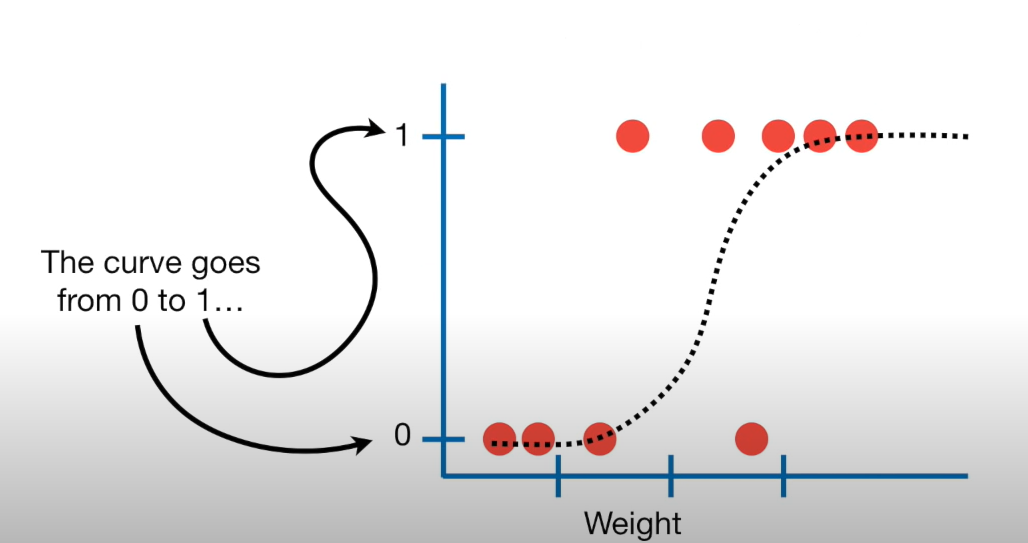
We want to fit an S curve (and not a straight line)…
where we model the probability of success as a function of explanatory a variable(s)
Example Figure:

Recap
With a categorical response variable, we use the logit link (logistic function) to calculate the log odds of a success
\(\widehat{ln(\frac{p}{1-p})}\) = \(\widehat{\beta_o} +\widehat{\beta}_1X1 + ....\)
We can use the same model to estimate the probability of a success
\[\hat{p} = \frac{e^{\widehat{\beta_o} + \widehat{\beta_1}X1 + ...}}{1 + e^{\widehat{\beta_o} + \widehat{\beta_1}X1 + ...}}\]
![]()